Introduction
This article looks at how Playwright text selectors work and the subtle differences between the various options. Though the example code uses Java, the underlying logic should be valid for all Playwright languages.
Source
The code resource for this article can be found in this github repository. The Playwright version used here is 1.22.
Text Selectors
These match the text contained in the text nodes of html elements in a page. Multiple variations of these are available. This can either be passed directly to the locator method or used as a css psuedo-class. We will look at each of these variations in action with the help of examples.
- “text=matcher”
- text=”matcher”
- “matcher”
- “text=regex”
- css:has-text(“matcher”)
- css:text(“matcher”)
- css:text-is(“matcher”)
- css:text-matches(“regex”)
“text=matcher”
The selector matches the smallest html element that contains the text. The match can be for a text node or combination of texts in all the nodes contained in an element. This will be much more clear from the examples. This selector is case-insensitive and also searches for substring. Usage examples can be found here.
Simple content – <span id=’container’>Playwright is easy to use</span>
The span will be selected by these selector usages – “text=Playwright is easy to use” , “text=PLAYWRIGHT IS EASY TO USE” and “text=Playwright”.
// Exact match
page.locator("text=Playwright is easy to use");
// Case insensitive match
page.locator("text=PLAYWRIGHT IS EASY TO USE");
// Substring match
page.locator("text=Playwright");Complex content – <span id=’container’>Playwright handles<span id=’outer1′> most of <span id=’inner’>the irritating <span id=’deep’>things</span></span> about </span>browser <span id=’outer2′>automation. </span>Happy learnings!</span>
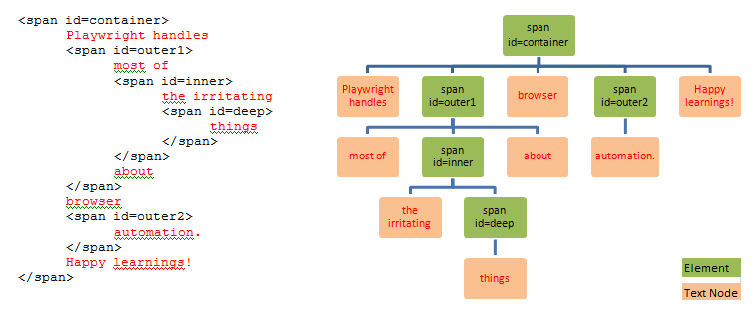
Things get interesting when we look at text matching for html element with multiple text nodes. To select the span with id=inner the simplest is to use the selector “text=the irritating”. This span can also be selected by using the text of span id=deep with the following – “text=the irritating things”.
Better yet, any substring match of the text “the irritating things” will work, for example “text=ing thin”.
It is important to remember that using the text as “things” or substring of only “things” will select the span with id=deep.
//Text match span id=inner
page.locator("text=the irritating");
//Text + span=deep text match span=inner
page.locator("text=the irritating things");
//Text + span=deep text substring match span=inner
page.locator("text=ing thin");
//FAIL span=deep text match
page.locator("text=things");Let us have a look at various ways to select the span with id=outer1. The span will be selected by these selector usages – “text=most of”, “text=about”, “text=of the”, “text=ings abo”, “text=most of the irritating things about”.
Do remember that text and substrings which match “the irritating” and ” things” will select span with id=inner or span with id=deep respectively.
//Text match span id=outer1
page.locator("text=most of");
page.locator("text=about");
// Text + child span text substring match span=outer1
page.locator("text=of the");
page.locator("text=ings abo");
//FAIL child span text match
page.locator("text=the irritating");
page.locator("text=things");text=”matcher”
This selector matches the html element with the text node with the exact text. This selector is case-sensitive and does not search for substring. Usage examples can be found here.
Simple content – <span id=’container’>Playwright is easy to use</span>
The span will be only selected by the exact match selector – “text=Playwright is easy to use”.
// Exact match
page.locator("text='Playwright is easy to use'");
// FAIL Case insensitive match
page.locator("text='PLAYWRIGHT IS EASY TO USE'");
// FAIL Substring match
page.locator("text='Playwright'");Complex content – <span id=’container’>Playwright handles<span id=’outer1′> most of <span id=’inner’>the irritating <span id=’deep’>things</span></span> about </span>browser <span id=’outer2′>automation. </span>Happy learnings!</span>
It does not matter how complex the html structure is, the element with the exact matching text node is selected. To select span with id=deep, use text=”things”. For span with id inner, use text=”the irritating”. To select span with id=outer1, the following selectors will work – text=”most of” and text=”about”.
// Exact match span id=deep
page.locator("text='things'");
// Exact match span id=inner
page.locator("text='inner'");
// Exact match span id=outer1
page.locator("text='most of'");
page.locator("text='about'");“matcher”
This works exactly like the text=”matcher” selector. Any string passed to the page.locator(“”) method will treated as a selector.
“text=regex matcher”
This selector matches the regular expression with the text contained in the html element. This will select the smallest html element which matches the text. The selection logic is same as the “text=matcher” selector.
css:has-text(“matcher”)
This selector matches any element, restricted by the css selector, containing the specified text in its hierarchy. The matching is case-insensitive and searches for a substring. Usage examples can be found here.
Simple content – <span id=’container’>Playwright is easy to use</span>
The span will be selected by these selector usages – “span:has-text(‘Playwright is easy to use’)” , “span:has-text(‘PLAYWRIGHT IS EASY TO USE”‘) and “span:has-text(‘Playwright’)”.
// Exact match
page.locator("text=Playwright is easy to use");
// Case insensitive match
page.locator("text=PLAYWRIGHT IS EASY TO USE");
// Substring match
page.locator("text=Playwright");Complex content – <span id=’container’>Playwright handles<span id=’outer1′> most of <span id=’inner’>the irritating <span id=’deep’>things</span></span> about </span>browser <span id=’outer2′>automation. </span>Happy learnings!</span>
Let us have a look what happens when we use the selector span:has-text(“things”). This will return the following span elements in the hierarchy that contain this text – id=deep, id=inner, id=outer1 and id=container.
Similarly if we use span:has-text(“automation.”) the following span elements are returned – id=outer2 and id =container.
A simple way to restrict the number of elements is to make the css selector more specific, like in this case, by adding an id like span#deep:has-text(“things”).
// Match all elements in heirarchy. Count 4.
page.locator("span:has-text('things')");
// Match all elements in heirarchy. Count 2.
page.locator("span:has-text('automation.')");
// Restrict match to span id=deep
page.locator("span#deep:has-text('things')");To select the span with id=inner the following usages will work – span#inner:has-text(“the irritating”), span#inner:has-text(“things”), span#inner:has-text(“the irritating things”), span#inner:has-text(“THE IRRITATING THINGS”), span#inner:has-text(“irritating things”).
The first two match the text nodes contained inside the span. The third one matches the combination text of the nodes. The fourth is a case-insensitive match and the fifth a substring match.
// Match span id=inner text node
span#inner:has-text("the irritating")
span#inner:has-text("things")
// Match span id=inner node combination
span#inner:has-text("the irritating things")
// Match span id=inner case-insensitive node combination
span#inner:has-text("THE IRRITATING THINGS")
// Match span id=inner substring node combination
span#inner:has-text("irritating things")css:text(“matcher”)
This works exactly like the “text=matcher” but restricted by the css selector. Usage examples can be found here.
css:text-is(“matcher”)
This works exactly like the text=”matcher” but restricted by the css selector. Usage examples can be found here.
css:text-matches(“regex matcher”)
This works exactly like the “text=regex matcher” but restricted by the css selector.